Project Description
OpenMind: Government AI with Uncompromising Accuracy
OpenMind is an accuracy-first AI system designed specifically for government systems. It addresses the critical challenge of deploying AI in governmental contexts where 99%+ accuracy is required and hallucination is unacceptable.
We achieve 99%+ level of accuracy by using a multi state model and provide complete transparency of the complete flow taken by the system to generate the response based on the query.
Key Innovations
Dataset-Bounded AI that only responds based on the available data. The model would politely decline to any requests that. cannot be answered based on the given data and simply deny to respond to the user prompt.
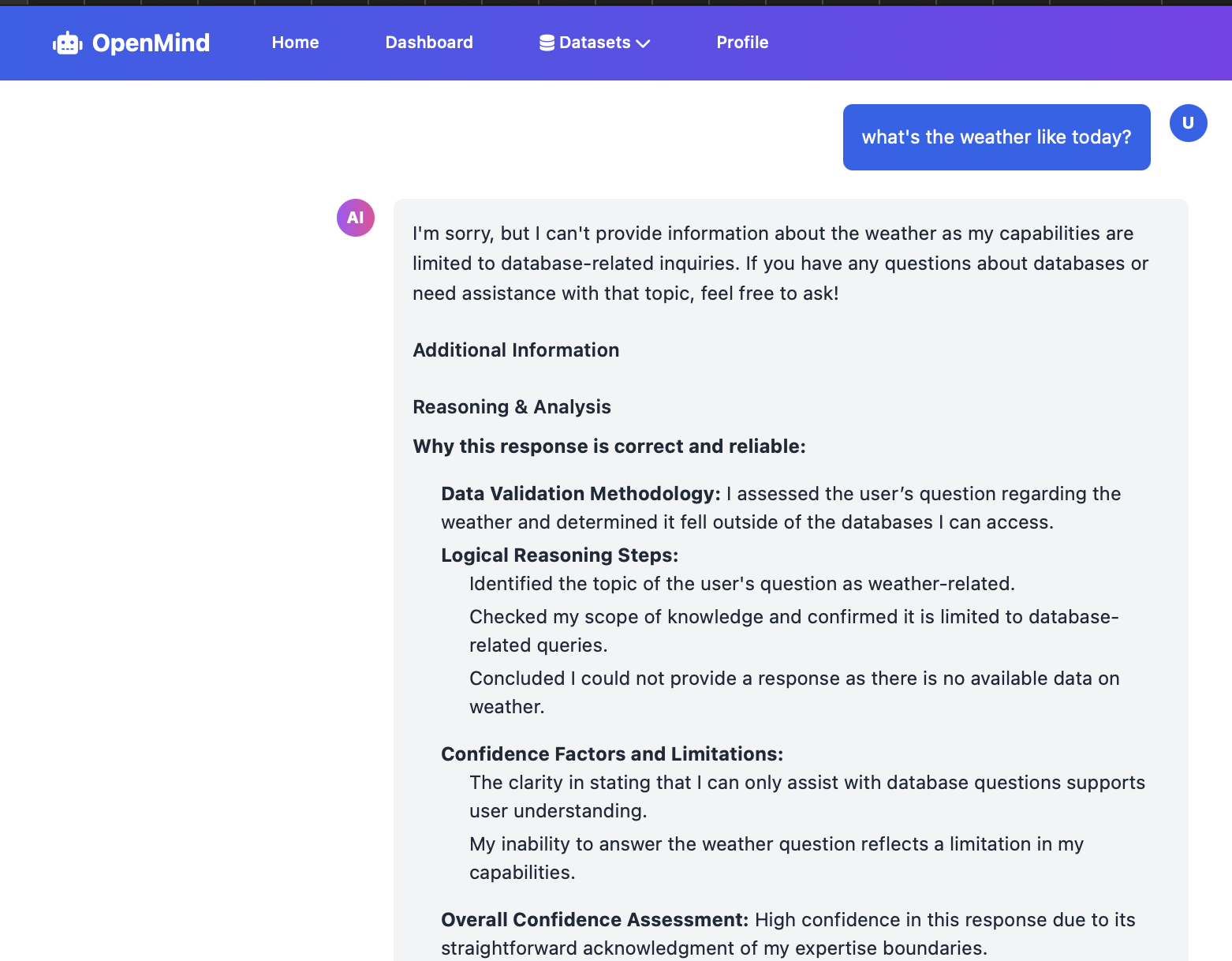
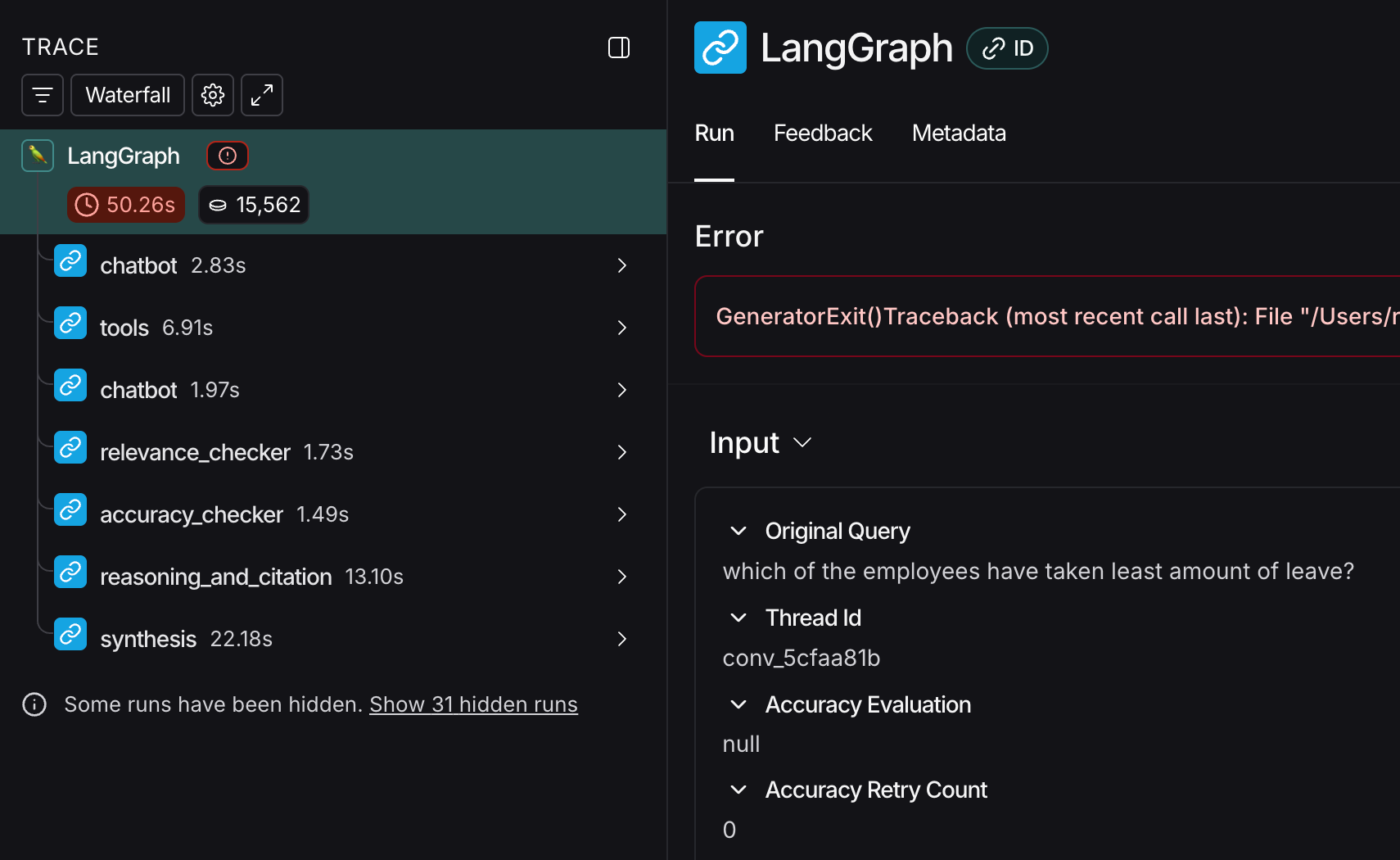
The deployment provides trace to each and every query asked to the model. This is most important in government work for auditing and validating the responses.
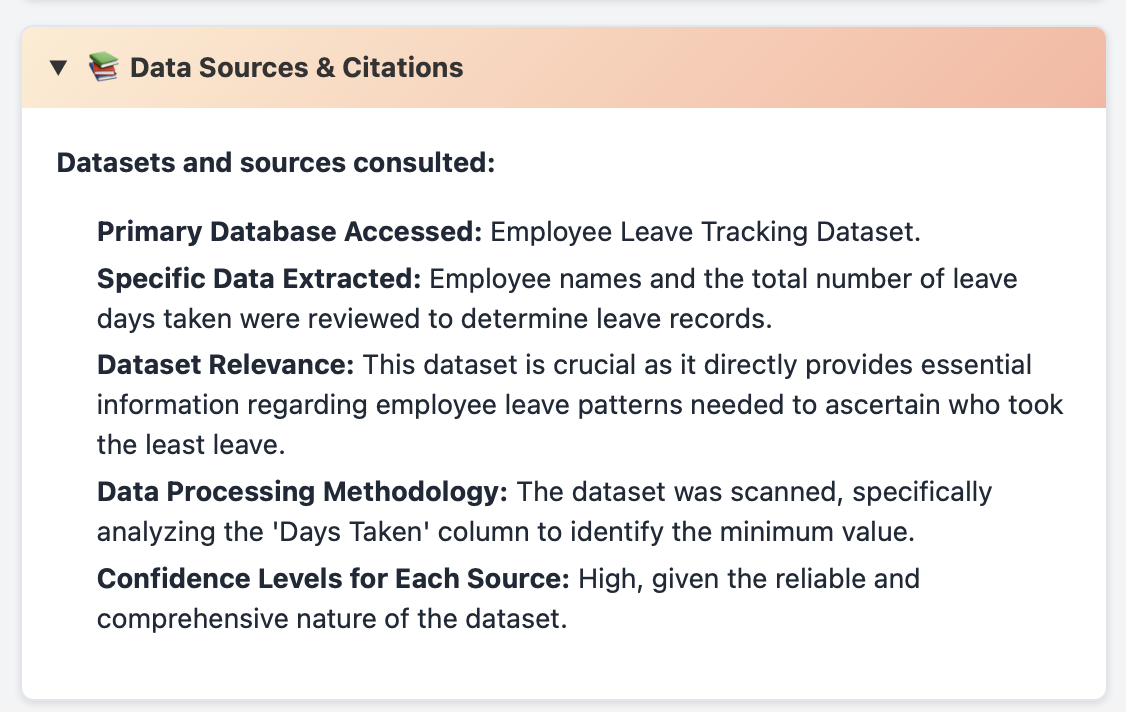
Complete citations and referenced datasets are provided with each query so that the user can easily verify or research deeper on the actual data.
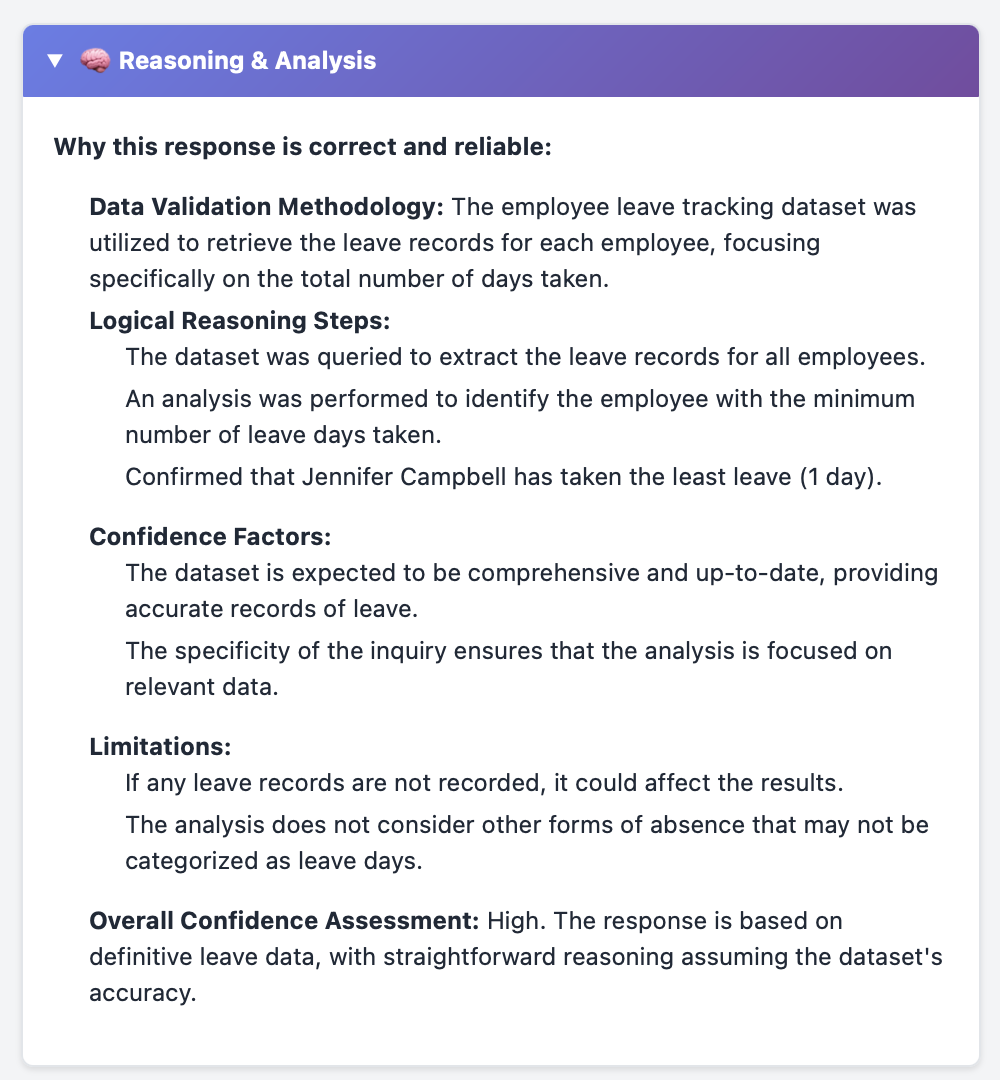
The model provides accurate reasoning which is validated by another higher accuracy model to ensure the response stems from accurate logic and correct dataset.
Architecture Diagram

How does it work?
We have used lang graph state machines to orchestrate the whole workflow. There are 4 different tools that will be used by the application.
- BasicTool (this is the SQL Executor for now)
- Relevance Checker Tool
- Accuracy Checker Tool
- Chatbot (Actual LLM)
- Citation and Sourcing Checker Tool.
The way the flow works is chatbot is the middle bot which orchestrates all other states. After running the query to fetch the data using the BasicTool - it checks for relevance, accuracy and provides citation with the data as well. This increases the accuracy of the platform.
Data Story
We evaluated the models with different datasets and prompts and found out grok-4o-mini to appropriately run the correct queries with low token cost. This makes the solution approachable and effective.
We also wrote a simple evaluation framework eval.py which takes a ground truth and evaluates the response of the model whether it matches the ground truth.
The data was critical to drive the evaluation framework and for choosing the appropriate model, along with correct stages and states in the lang graph model.
